1. 신경망의 학습
신경망의 학습이란 학습데이터를 가지고 신경망의 가중치 와 바이어스를 업데이트 하여 오차를 줄이고 원하는 결과값을 얻을 수 있도록 하는 기법이다.
2. 오차의 역전파
신경망의 학습 과정을 통해 입력데이터에 대한 결과를 가지고 정답과 비교한 오차를 출력층 -> 은닉층으로 순전파의 반대 방향으로 가중치를 업데이트 해 나가는 방법을 말한다.
3. 손실함수(비용함수,오차함수)
여러 이론책에 다양하게 표현되나 같은 뜻을 가지고 있다. 신경망의 성능을 나타내고자 하는 지표로 신경망의 역전파 과정에 사용 된다.
손실함수로는 평균 제곱 오차(MSE) 와 교차 엔트로피 오차(cross entropy,CEE) 함수가 가장 많이 사용 된다. 교차 엔트로피 함수는 오차가 커질 수록 비용이 급격하게 증가한다.
4. 원-핫 인코딩
학습과정에서 정답을 표기할 때 원-핫 인코딩 방식을 사용 하는데 한노드만 1로 출력 하고 나머지는 0으로 출력하여 정답인 노드를 1로 출력 하는 분류 모델에서 사용 방식 이다.
5. 가중치 값을 갱신하는 방법
경사하강법 (DG) : 100개의 학습 데이터가 있다면 가중치값이 100번 갱신된다.
배치 : 모든 학습 데이터의 하나로 묶어 가중치를 한번만 갱신 할 수있도록 하는 기법
미니 배치 : DG와 배치방식을 섞어 놓은 개념으로 전체 학습 데이터 중 일부 데이터만 골라서 배치 하는 방법
딥러닝에 많이 사용되는 방법은 미니 배치 방식 이다.
6. 경사하강법에서의 가중치와바이어스 갱신 방법
경사 하강법이란 손실함수 즉 결과가 오차가 주어지는 함수 에서 최솟값을 찾아가는 과정이라고 할 수 있다. 이 때 기울기를 이용하는데 손실 함수에서 기울기가 최소화 되는 값을 향해 조금씩 가중치와바이어스를 갱신 한다. 이때 기울기는 손실 함수를 미분하여 얻을 수 있다.
딥러닝 분야에서는 확률적 경사 하강법(SDG) 확률적으로 무작위로 골라낸 데이터에 대해 수행 하는 경사하강법을 이용한다.
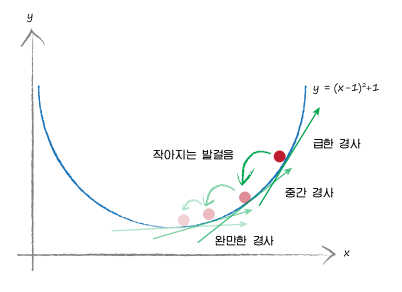
7. 학습률 (learning rate)
학습률은 미분한 손실함수의 값에서 일정 값을 곱하여 가중치와 바이어스의 갱신률을 조정 하는데 사용되어 진다.
참고:
딥러닝첫걸음 - 머신러닝에서 컨벌루션 신경망까지 / 김성필 | 한빛미디어
밑바닥부터 시작하는 딥러닝 - 파이썬으로 익히는 딥러닝 이론과구현 / 사이토고키 | 한빛미디어
신경망첫걸음 - 수포자도 이해하는 신경망 동작 원리와 딥러닝 기초 / 타리크라시드 | 한빛 미디어











{kind=link}